















Ready to apply?
Amazing! You’re well on your way to joining our team and going one better in your career. Follow the link below to find the perfect job for you.
For our people. For our players. For our future.
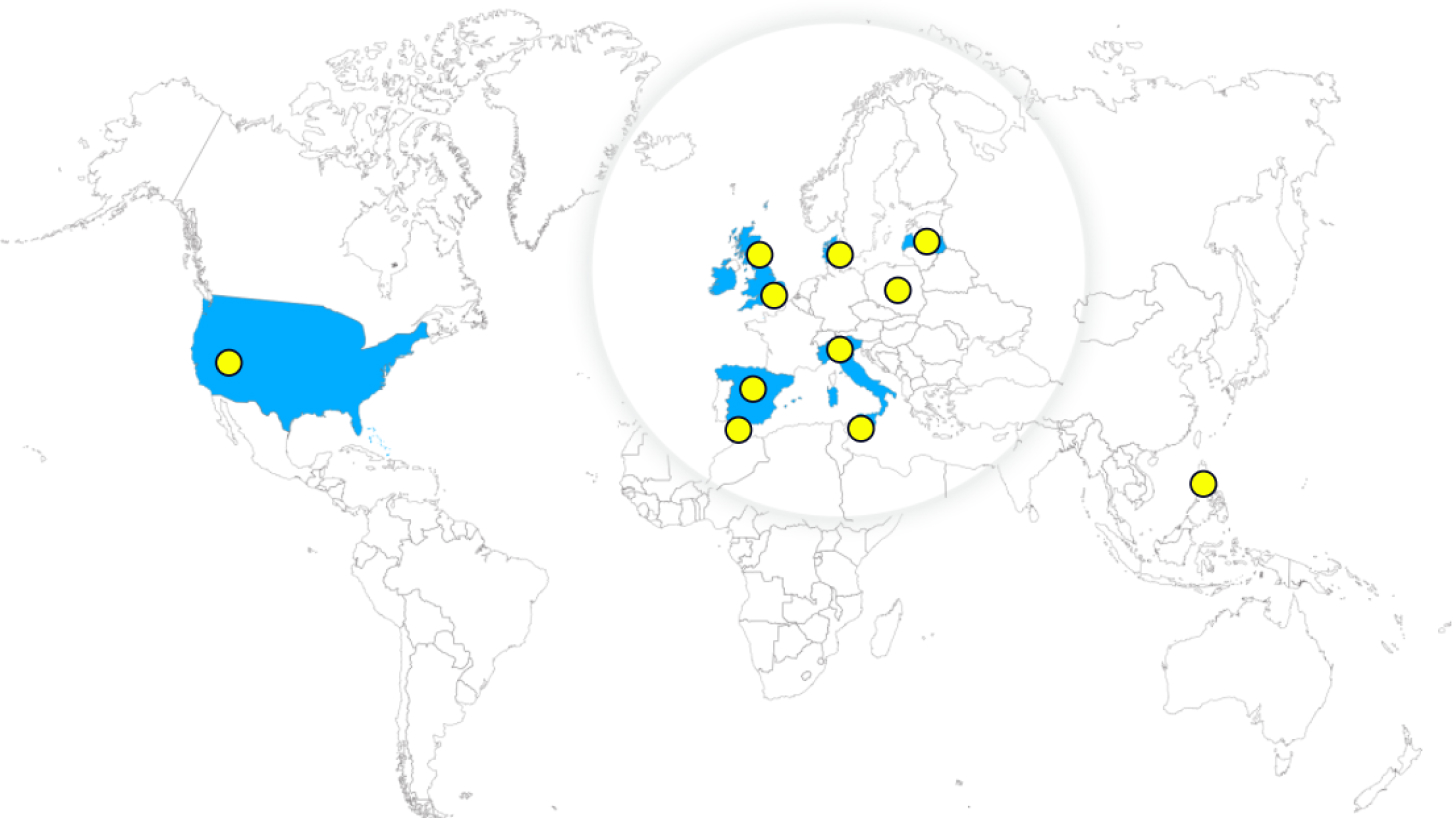
At William Hill, we embrace change and progress — it’s what keeps us ahead of the pack. Since we got going in 1934, we’ve put in hard graft to become one of the largest global sports betting and gaming companies. We’re building a better business together, where you'll have the support and encouragement to celebrate what makes you different and build a career that goes one better.
Following in the entrepreneurial footsteps of our founder, we’re continuing to build an international and multi-brand business.
Customer
We’re committed to offering entertaining, industry-leading products to our customers across all our markets. To deliver on our commitment, we’ll ensure continuous innovation, increased personalisation, best-in-class customer support and customer protections.
Team
Our people are talented achievers who are passionate, driven, and ambitious, and we have created an environment where people want to join us and love to stay. We continue to drive a culture of collaboration, inclusion and engagement and always strive to have world-class capabilities across our global business.
Execution
We always want to be known as a company that deliver on our promises. We will continue to build scale and deliver industry leading operational efficiency. This will help us drive sustainable and profitable revenue growth, whilst always ensuring operational compliance excellence.
Andrew Lowrey
Global Head of Product
Creating a market-leading set of fun products is what we're all about. My team is passionate, dedicated – and we work together to make things better for our customers every day.
Angela Clarke
Customer Experience Manager
William Hill are so accommodating. They really care about my family situation and give me the flexibility I need to balance my work with childcare.

